
2026 год стал переломным для корпоративного ИИ: рынок перешёл от экспериментов к внедрению, а главный тренд — агентные системы, которые самостоятельно выполняют задачи и принимают решения на основе данных компании.
У большинства компаний корпоративные данные уже есть: история клиентов в CRM, показатели в ERP, договоры в архивах, задачи в Jira. Но все системы изолированы — и чтобы получить полную картину, сотрудник вручную обходит пять разных интерфейсов. Например, менеджер, который готовит коммерческое предложение, тратит сорок минут не на работу с клиентом, а на сбор данных о нём.
Корпоративная ИИ-база знаний решает именно эту проблему. В статье разберём, как она объединяет разрозненные источники, что происходит «под капотом» при каждом запросе — и какой профит для бизнеса.
Если в 2023–2024 годах компании внедряли чат-боты, то сейчас основной драйвер — ИИ-агенты или ИИ-базы знаний. Примерно 70% CEO фокусируются на росте выручки, и компании с ИИ уже показывают в разы больший доход на одного сотрудника, чем без него.
ИИ-база знаний — это система, которая объединяет корпоративные данные из разных платформ и делает их доступными для поиска по смыслу. Она подключается к источникам компании и обрабатывает их содержимое в том виде, в котором они уже существуют.
Сотрудник задаёт вопрос в свободной форме и получает точный ответ с опорой на внутренние документы.
Юристу, чтобы найти условия форс-мажора во всех контрактах за несколько лет, приходится открывать папки с PDF-сканами и вручную просматривать десятки документов. На это уходят часы и дни, при этом мы не исключаем риски ошибки из-за человеческого фактора.
У менеджера по продажам примерно похожая ситуация: данные о клиенте — в CRM, прайс — в Excel, правила скидок — в PDF на общем диске, переписка — в почте. Сбор информации для одного коммерческого предложения занимает от 30 минут.
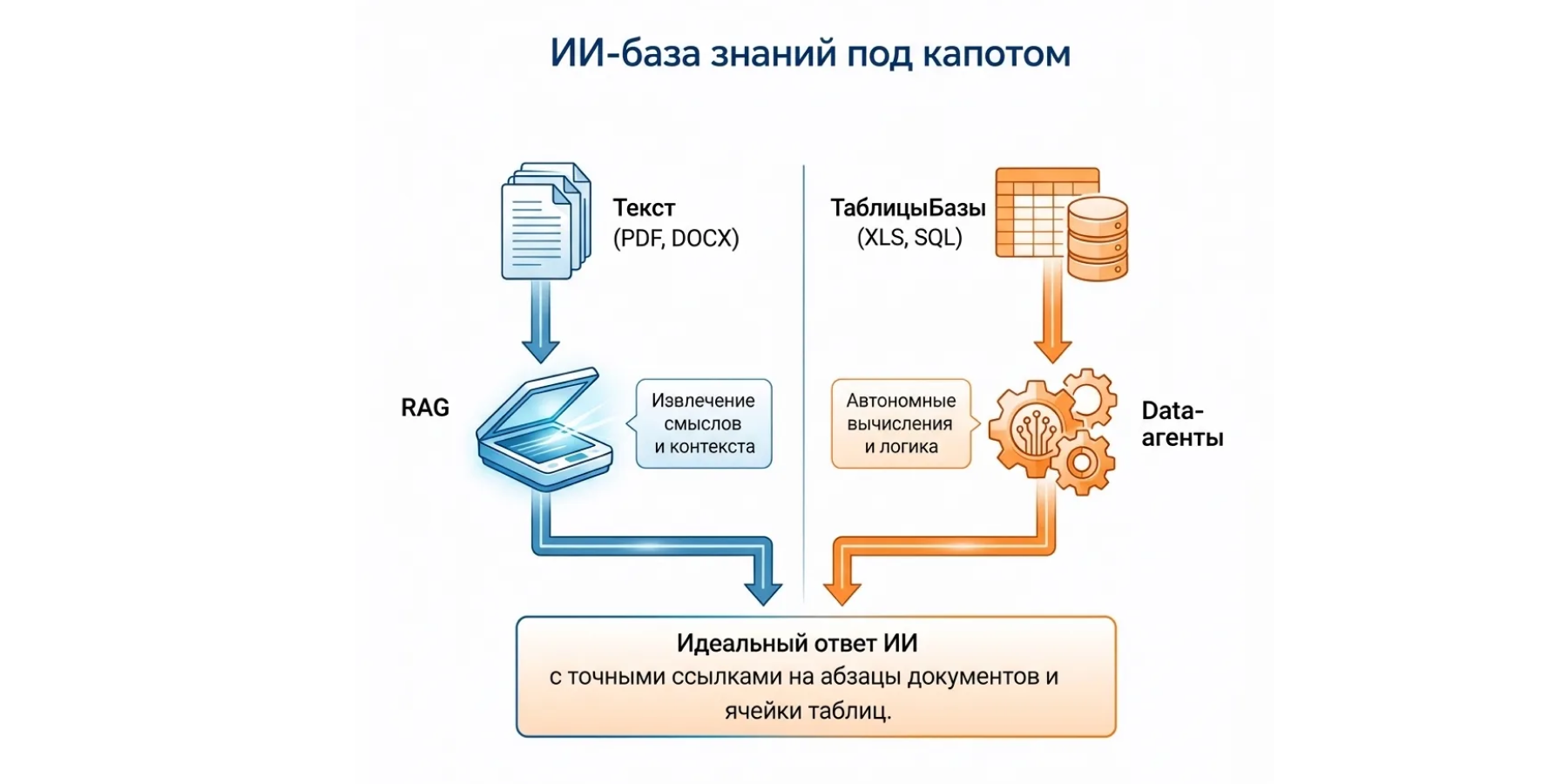
Архитектура ИИ-базы знаний строится вокруг простой логики: подключить источники, обработать данные и дать к ним быстрый доступ.
Система работает с данными в том виде, в котором они уже есть в компании. Это могут быть документы (PDF, DOCX), таблицы (XLS, CSV), базы данных, переписка, а также аудио и видео. Источники подключаются напрямую — через API или файловые хранилища. Переносить данные или приводить их к единому формату не требуется.
После подключения система автоматически разбирает содержимое: извлекает текст, структуру и связи между данными. В основе — смысловой анализ: система понимает, о чём документ.
Для текстовых документов применяется подход RAG: при запросе находятся релевантные фрагменты и используются для формирования ответа.
Для таблиц и баз данных подключаются отдельные механизмы, которые работают с числами напрямую: можно, например, посчитать стоимость или проверить остатки без ручной выгрузки.
Архитектура не привязана к одной языковой модели — её можно заменить без перестройки всей системы.
Сотрудники работают с базой знаний через привычные интерфейсы — корпоративные мессенджеры или внутренние системы. Запрос формулируется в свободной форме, а в ответ система возвращает также ссылки на конкретные источники: абзацы документов, строки таблиц, записи в базе.
Дополнительно система собирает аналитику по использованию: какие запросы возникают чаще, где не хватает данных или возникают ошибки.
|
Направление |
Описание |
|
Служба поддержки |
Система автоматически обрабатывает типовые запросы и подсказывает операторам контекстные ответы в режиме реального времени. |
|
Юридический отдел |
Поиск по договорам и нормативным актам занимает секунды. |
|
HR |
Новый сотрудник получает ответы об отпусках, льготах и правилах. |
|
Внутренняя техподдержка |
Help Desk разгружается — сотрудники сами находят инструкции по базе знаний. |
|
Аналитика |
Система агрегирует рыночные данные и готовит выжимки для топ-менеджеров. |
Внедрение корпоративных систем обычно ассоциируется с многомесячными проектами. Здесь схема другая.
Диагностика
Анализ бизнес-процессов, выбор архитектуры под конкретные задачи, формирование дорожной карты.
Интеграция
Подключение сторонних источников. Автоматическая обработка документов без ручной разметки.
Пилот и запуск
Тестирование качества ответов, настройка прав доступа по ролям, вывод в эксплуатацию.
Для более сложных проектов предусмотрен расширенный план с фазой пилота на ограниченной группе пользователей и последующим масштабированием.
ИИ-база данных не привязана к конкретному вендору. На выбор доступны облачные модели — OpenAI, DeepSeek, Сбер, Yandex, Т-Банк — и open-source: Llama-3, Qwen и другие.
Если данные не должны покидать инфраструктуру, то стоит выбрать open-source модель и разворачивать всё внутри корпоративного контура. Если приоритет — качество ответов или скорость запуска, подключаете облачную.
Архитектура не завязана на одну модель: если появится более точная или выгодная альтернатива, переключаетесь без перестройки базы знаний.
Корпоративные данные не передаются на внешние серверы. Доступ разграничен по ролям: каждый сотрудник видит только те источники, к которым у него есть права. Все запросы логируются — можно в любой момент проверить, кто, что и когда спрашивал. Данные в хранилищах шифруются.
100 тыс.+ пользователей и 3000 часов разработки — Flutter MVP за 3 месяца

Тысячи скачиваний и шорт-лист Рейтинга Рунета — экосистема доставки еды на Flutter для Пхукета
Flutter-приложение с ИИ-ментором — трекер привычек, который помогает обрести спокойствие и рост
Нет. ИИ-база знаний подключается к существующим системам. Данные остаются на месте — платформа только получает к ним доступ.
Базовый запуск занимает три дня. Первый — диагностика и выбор архитектуры, второй — подключение источников, третий — тестирование и запуск. Ручная разметка данных не требуется.
Система работает с любыми форматами: PDF, DOCX, XLS, CSV, SQL, аудио, видео. Приводить данные к единому виду не нужно. Единственное, что стоит определить заранее — какой источник считается главным, если одна и та же информация хранится в нескольких местах.
Права доступа настраиваются по ролям.Например, финансовые данные видит финансовый отдел, HR-документы — HR. Сотрудник получает ответ только из тех источников, к которым у него есть доступ.
Да. Система не привязана к конкретному вендору — поддерживаются OpenAI, DeepSeek, Сбер, Yandex, Т-Банк, Llama-3, Qwen. Если появится более точная или дешёвая модель, можно переключиться без перестройки системы.
Встроенная аналитика отслеживает качество ответов, фиксирует частые запросы и помечает случаи, где система не нашла достаточно данных. По трём реальным внедрениям точность составила 89–96%.



