
Python часто воспринимается как язык, в котором всё происходит «само собой»: написал код — получил результат. За таким «простым» процессом скрывается многоступенчатый механизм трансформации.
Каждая строка проходит через цепочку преобразований: от удобных человеку конструкций до инструкций, понятных машине. В этой статье разберёмся, как на самом деле работает Python под капотом и что происходит в тот момент, когда вы нажимаете run.
Когда вы вводите команду python script.py в терминале, запускается интерпретатор Python (стандартная реализация CPython). Выполнение кода python не начинается мгновенно — сначала происходит несколько подготовительных этапов.
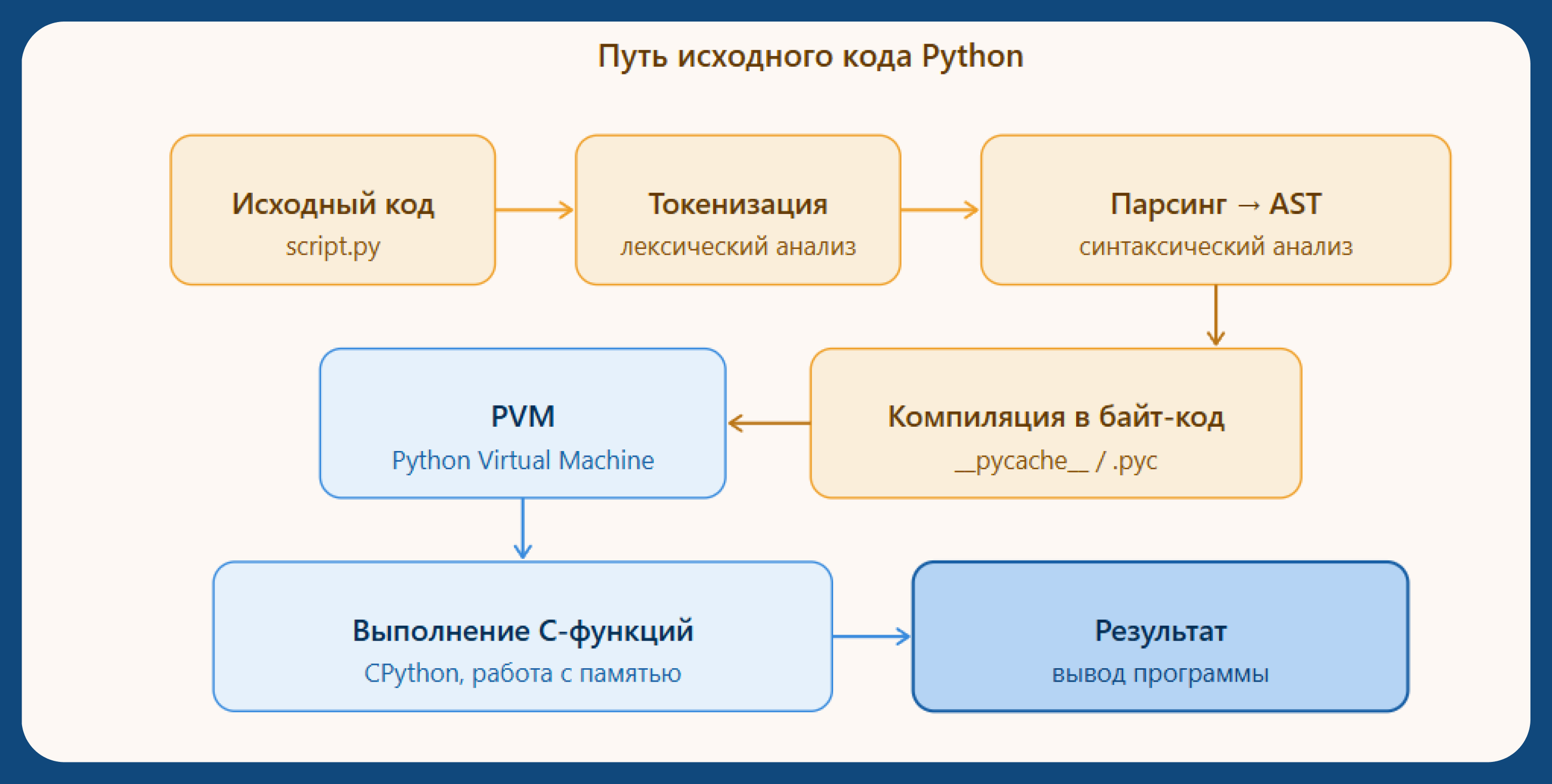
Python традиционно относят к интерпретируемым языкам, однако его работа сложнее: перед выполнением код компилируется в промежуточное представление — байт-код, который затем исполняется виртуальной машиной Python.
Разберём каждый этап подробно.
Первый этап работы CPython — компиляция исходного кода в байт-код. Он включает несколько последовательных шагов.
Исходный текст программы разбивается на минимальные значимые элементы — токены: ключевые слова, идентификаторы, операторы и скобки. На этом этапе игнорируются комментарии и незначащие пробелы, но отступы в Python являются частью синтаксиса.
Полученные токены преобразуются в абстрактное синтаксическое дерево (AST) — структуру, отражающую логику программы. Если в коде присутствуют синтаксические ошибки (например, пропущено двоеточие или нарушены отступы), они обнаруживаются именно на этом этапе.
Затем компилятор CPython проходит по узлам AST и генерирует инструкции байт-кода — низкоуровневого представления программы, предназначенного для выполнения виртуальной машиной Python. Именно поэтому Python можно считать компилируемым языком в определённом смысле.
Байт-код представляет собой низкоуровневый набор инструкций, не зависящий от архитектуры операционной системы или процессора. Он служит промежуточным звеном между исходным кодом и его выполнением.
Скомпилированные файлы сохраняются с расширением .pyc в директории __pycache__. Если исходный файл не изменялся, при последующих запусках Python использует уже готовый байт-код, что позволяет сократить время старта программы.
Байт-код — это не машинный код, исполняемый процессором. Он предназначен для выполнения внутри интерпретатора. Для преобразования Python-кода в нативный машинный код применяются дополнительные инструменты, такие как Cython или Nuitka.
После генерации байт-кода управление передаётся Python Virtual Machine (PVM) — виртуальной машине, отвечающей за его выполнение. PVM представляет собой стековый интерпретатор, который последовательно считывает и исполняет инструкции байт-кода.
В основе её работы лежит стековая архитектура. Например, при сложении двух чисел значения сначала помещаются на стек, затем выполняется соответствующая операция, после чего результат возвращается на вершину стека и используется в дальнейших вычислениях.
Большинство повседневных операций, таких как конкатенация строк, работа со списками или математические вычисления со встроенными типами, реализовано в CPython на C.
Когда вы вызываете метод my_list.append(1), виртуальная машина Python (PVM) не интерпретирует логику добавления элемента на уровне Python. Вместо этого она обращается к оптимизированной функции на C, которая напрямую управляет памятью и выполняет операцию максимально эффективно. Такой подход позволяет сочетать удобство Python с производительностью низкоуровневых языков.
Вопрос производительности Python связан с его архитектурными особенностями. Чтобы лучше понять различия, сравним Python с компилируемыми языками, такими как C и C++.
В языках вроде C++ тип переменной известен на этапе компиляции. В Python же при каждой операции, например a + b, интерпретатор должен определить:
Эти многочисленные проверки во время выполнения (runtime checks) создают дополнительные накладные расходы.
PVM должна обрабатывать каждую инструкцию байт-кода прямо во время выполнения. Современные JIT-компиляторы (как в PyPy или V8 в JavaScript) пытаются это оптимизировать, но классический CPython работает именно так.
Это «замок», который позволяет только одному потоку управлять интерпретатором Python в единицу времени. Это упрощает управление памятью, но не даёт Python эффективно использовать многоядерные процессоры для параллельных вычислений в CPU-bound задачах.
Python автоматически управляет памятью с помощью подсчёта ссылок (Reference Counting) и сборщика мусора (Garbage Collector). Хотя это избавляет разработчика от необходимости вручную освобождать ресурсы, такие механизмы требуют дополнительных вычислительных затрат.
Несмотря на медлительность чистого Python, библиотеки вроде NumPy, Pandas и TensorFlow работают в десятки раз быстрее. Секрет в том, их вычислительно тяжёлые части реализованы не на чистом Python.
1. Библиотеки на C/C++/Rust. NumPy и Pandas используют массивы, и внутренние структуры данных, реализованные на низкоуровневых языках. Когда вы вызываете np.array([1, 2, 3]).sum(), Python делегирует вычисление быстрой C-функции, которая работает напрямую с памятью.
2. Векторизация операций. Вместо цикла for на Python, который медленно итерируется, NumPy выполняет операцию над всем массивом сразу через оптимизированный C-код.
3. Минимум проверок типов. В C-библиотеках типы данных фиксированы заранее (например, float64), поэтому не нужно проверять типы на лету.
# Медленно (чистый Python)
result = sum([i * 2 for i in range(1000000)])
# Быстро (NumPy, в 50-100 раз)
import numpy as np
result = np.sum(np.arange(1000000) * 2)Python жертвует скоростью ради гибкости, но делегирует тяжёлые вычисления быстрым библиотекам.
Python изначально проектировался не как замена C или Java, а как язык, в котором код пишется быстро и читается легко. Скорость выполнения здесь намеренно принесена в жертву скорости разработки.
Многоуровневая архитектура добавляет накладные расходы, но даёт гибкость — один и тот же код работает на Windows, Linux и macOS без изменений. Там, где производительность критична, Python просто делегирует работу библиотекам на C, C++ других низкоуровневых языках (NumPy, pandas, PyTorch под капотом используют именно такие реализации).
Получается любопытная конструкция: вы пишете на Python, а тяжёлые вычисления выполняет скомпилированный код. Это объясняет, почему язык одинаково хорошо прижился и в веб-бэкенде, и в машинном обучении, и в научных расчётах — областях с совершенно разными требованиями к производительности.
С технической точки зрения Python можно считать компилируемым в байт-код, но не в машинный код напрямую. Именно поэтому его часто называют интерпретируемым языком с предварительной компиляцией. Такой гибридный подход обеспечивает переносимость и удобство разработки, сохраняя приемлемый уровень производительности.
100 тыс.+ пользователей и 3000 часов разработки — Flutter MVP за 3 месяца

Тысячи скачиваний и шорт-лист Рейтинга Рунета — экосистема доставки еды на Flutter для Пхукета





